Pre-Print meines neuen TikZ-Artikels, Teil 2
In Pre-Print meines neuen TikZ-Artikels hatte ich den Folgeteil versprochen, der ist jetzt auch soweit gediegen, dass ich ihn präsentieren kann.
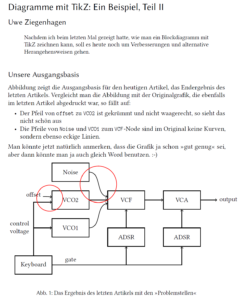
Textsatz mit \LaTeX, Programmieren, Zahlen, etc.
Posts tagged ‘LaTeX’
In Pre-Print meines neuen TikZ-Artikels hatte ich den Folgeteil versprochen, der ist jetzt auch soweit gediegen, dass ich ihn präsentieren kann.
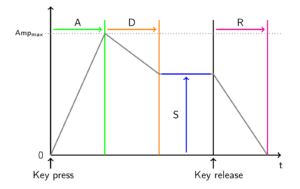
Hier die Darstellung einer ADSR Hüllkurve (Quelle: Wikipedia) mit TikZ:
\begin{tikzpicture} %\draw[step=0.5cm,lightgray,thin] (0,0) grid (10,7); \draw[very thick, black,->](1,1) -- (9.5,1); \draw[very thick, black,->](1,1) -- (1,6.5); \draw[very thick, green,](3,1) -- (3,6); \draw[very thick, orange,](5,1) -- (5,6); \draw[very thick, black](7,1) -- (7,6); \draw[very thick, magenta](9,1) -- (9,6); \draw[very thick, gray,](1,1) -- (3,5.5) -- (5,4) -- (7,4)--(9,1); % max amp line \draw[thick, gray,dotted](0.8,5.5) -- (9.5,5.5); \draw[very thick, blue,->](6,1.1) -- (6,3.9); \draw[very thick, green,->](1.1,5.65) -- (2.9,5.65); \draw[very thick, orange,->](3.1,5.65) -- (4.9,5.65); \draw[very thick, blue](5.1,4) -- (6.9,4); \draw[very thick, magenta,->](7.1,5.65) -- (8.9,5.65); \node[label=left:0] (A) at (1,1) {}; \node[label=below:t] (B) at (9.5,1) {}; \node[label=left:{{\scriptsize Amp\textsubscript{max}}}] (C) at (1,5.5) {}; \node[label=above:A] (D) at (2,5.5) {}; \node[label=above:D] (E) at (4,5.5) {}; \node[label=left:S] (F) at (6,2.5) {}; \node[label=above:R] (G) at (8,5.5) {}; \draw[very thick, black,->](1,0.5) -- (1,0.9); \draw[very thick, black,->](7,0.5) -- (7,0.9); \node[label=above:{Key press}] (D) at (1.1,-0.2) {}; \node[label=above:{Key release}] (D) at (7.2,-0.2) {}; \end{tikzpicture} |
Unter https://www.youtube.com/watch?v=WMCj_EPDms8 ist jetzt das geschnittene Video meines Vortrags zur „Formularerstellung mit eforms“ online.
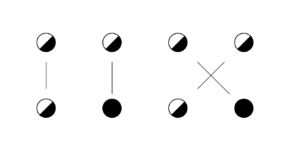
Hier ein kleiner Schnipsel TikZ, den ich für die Beantwortung einer LaTeX-Frage geschrieben habe.
\documentclass[fontsize=12pt]{scrartcl} \usepackage{wasysym} \usepackage{tikz} \usepackage[right]{showlabels} \usetikzlibrary{positioning} \usepackage{graphicx} \newcommand{\half}{\rotatebox{-45}{\Huge\RIGHTcircle}} \newcommand{\full}{\Huge\CIRCLE} \begin{document} \begin{center} \begin{tikzpicture}[x=20mm,y=20mm] \node at (0,0) (a1) {\half}; \node at (1,0) (a2) {\half}; \node at (2,0) (a3) {\half}; \node at (3,0) (a4) {\half}; \node at (0,-1) (b1) {\half}; \node at (1,-1) (b2){\full}; \node at (2,-1) (b3) {\half}; \node at (3,-1) (b4) {\full}; \draw (a1) -- (b1); \draw (a2) -- (b2); \draw (a3) -- (b4); \draw (a4) -- (b3); \end{tikzpicture} \end{center} \end{document} |
Bei golem.de wurde mein zweiter LaTeX-Artikel veröffentlicht, ihr findet ihn hier: https://www.golem.de/news/layouten-mit-latex-setzt-du-noch-oder-gestaltest-du-schon-2207-165543.html
Der erste Artikel zum Thema befindet sich hier: https://www.golem.de/news/latex-schreibst-du-noch-oder-setzt-du-schon-2201-162303.html
Hier die Folien meines MyTinyTodo2LaTeX Lightning Talks, gehalten auf der Sommertagung 2022 von Dante e.V. in Magdeburg.
Für LuaLaTeX gibt es mit showhyphenation und showkerning zwei interessante Pakete, die die möglichen Trennstellen bzw. das Kerning anzeigen.
%!TEX TS-program = lualatex \documentclass[12pt,ngerman]{scrartcl} \usepackage[utf8]{inputenc} \usepackage[T1]{fontenc} \usepackage{babel} \usepackage{blindtext} \usepackage{microtype} \usepackage{showhyphenation} \usepackage[ontop]{showkerning} \begin{document} \blindtext \blindtext \end{document} |

Hier ein Beispiel für das XCharter Paket, das einen passenden Mathe-Font für die Charter bereitstellt.
%!TEX TS-program = LuaLaTeX \documentclass[12pt,ngerman]{scrartcl} \usepackage{fontspec} \usepackage{babel} \usepackage{unicode-math} \setmathfont{XCharter-Math.otf} % Call by file name or \setmathfont{XCharter Math} % Call by font name \setmainfont{XCharter} \setsansfont{Cabin}[Scale=MatchLowercase] % sf \setmonofont{Inconsolatazi4}[Scale=MatchLowercase] % tt \usepackage{blindtext} \begin{document} \blindtext \begin{equation} \int_{x=1}^{\infty} -\frac{p}{2} \pm \sqrt{ \left(\frac{p}{2} \right)^2 -q } \end{equation} \blindtext \end{document} |

Hier ein Beispiel dafür, wie man mit dem gridpapers Paket Muster auf Papier bringen kann, hier ein Punktmuster.
%!TEX TS-program = Arara % arara: pdflatex: {shell: yes} \documentclass[12pt,ngerman]{scrartcl} \areaset{8cm}{16cm} \usepackage[utf8]{inputenc} \usepackage[T1]{fontenc} \usepackage{babel} \pagestyle{empty} \usepackage[pattern=dot,% colorset=std, geometry={left=2.25cm,right=1.25cm,top=1cm,bottom=1.25cm},% textarea,% patternsize={5mm},% dotsize={1pt} ]{gridpapers} \begin{document} ~ \end{document} |
Auszug aus der A4-Seite:

Hier ein kurzes Beispiel, wie man mit LaTeX auch Dymo-Labels erzeugen kann, im Beispiel für die Label-Größe 57*32mm. Zum allgemeinen Verständnis von ticket.sty siehe auch meinen DTK Artikel in Ausgabe 1/2021.
\documentclass{article} \usepackage[T1]{fontenc} \usepackage{graphicx} \usepackage[landscape,paperheight=57mm,paperwidth=32mm,left=0mm,top=0mm,right=0mm,bottom=0mm]{geometry} %\usepackage[sfdefault]{plex-sans} \usepackage{palatino} \begin{filecontents}[overwrite]{Dymo5732.tdf} \unitlength=1mm \hoffset=-25.4mm \voffset=-29mm \ticketNumbers{1}{1} \ticketSize{57}{32} % Breite und Hoehe der Labels in mm \ticketDistance{0}{0} % Abstand der Labels \end{filecontents} \usepackage[Dymo5732]{ticket} \renewcommand{\ticketdefault}{}% \makeatletter \@boxedfalse % Rahmen um Ticket \@emptycrossmarkfalse % Falzmarken \@cutmarkfalse % Schnittmarken \makeatother \newcommand{\myticket}[2]{ \ticket{% \put(10,10){\scalebox{#1}{\bfseries #2}} }} \newcommand{\myticketml}[4]{ \ticket{% \put(5,20){\scalebox{#1}{\bfseries #2}} \put(5,15){\scalebox{#1}{\bfseries #3}} \put(5,10){\scalebox{#1}{\bfseries #4}} }} \begin{document} \myticketml{1.25}{Dr. Max Mustermann}{Musterweg 123}{54321~Musterstadt} \myticket{2}{Steuern} \end{document} |