2022-03-20, 22:41
Über eine Verknüpfung auf die Rundll32.exe kann man flink in den Energiesparmodus von Windows wechseln.
In irgendeinem Ordner (z.B. auf dem Desktop) rechte Maustaste => neu => Verknüpfung. Als Speicherort des Elements dann folgendes eingeben:
C:\Windows\System32\rundll32.exe powrprof.dll,SetSuspendState
2022-03-19, 20:52
Hier noch ein weiteres Beispiel, wie man sich mit Python sinnlose manuelle Arbeiten erleichtern kann. Gegeben sei die folgende Verzeichnisstruktur:
Verzeichnis1
Ordner1
Unterordner1
Willich.txt
Ordner2
Unterordner2
Willich.txt
Ordner3
Unterordner3
Willich.txt
Die in den Ordnern liegenden Dateien sind alle gleich benannt (trotz unterschiedlicher Inhalte), sollen aber für die weitere Verarbeitung in einen Ordner verschoben werden. Man kann sie jetzt manuell nach dem Schema „Ordnerx-Unterordnerx-Dateiname“ umbenennen, man kann es aber auch lassen und ein kurzes Python-Skript dazu schreiben. Spätestens bei 20 oder 30 Dateien lohnt sich der Aufwand der initialen Entwicklung, das Beispiel lässt sich auch leicht auf andere Aufgaben übertragen. Die folgende Python-Datei speichert man in „Verzeichnis1“, dieses Verzeichnis bildet dann den root-Pfad. Der Rest ist dann einfach nur cleveres Auswerten des Pfades und das Wechseln der Backslashes in Unterstriche, um den neuen Pfad zu bauen.
import os
for (root,dirs,files) in os.walk('.'):
for file in files:
fullpath = os.path.join(root,file)
if fullpath.endswith('.txt'):
newpath = root+'\\'+root[2:].replace('\\','_')+'_'+file
print(newpath)
os.rename(fullpath, newpath) |
import os
for (root,dirs,files) in os.walk('.'):
for file in files:
fullpath = os.path.join(root,file)
if fullpath.endswith('.txt'):
newpath = root+'\\'+root[2:].replace('\\','_')+'_'+file
print(newpath)
os.rename(fullpath, newpath)
2022-03-19, 20:20
Vor kurzem hatte ich die Herausforderung, diverse XML Dateien zu kombinieren, die aufgrund einer Größenbeschränkung in einzelne, jeweils eigenständige, Dateien zerlegt worden waren. In jeder Datei fanden sich XML-Metaangaben in den ersten zwei und der letzten Zeile. Die Aufgabe bestand nun darin, den XML-Kopf und das XML-Ende nur einmal in der Ausgabedatei zu haben. An der folgenden Text-Datei kann man das gut erkennen:
Will ich nur einmal am Anfang
Will ich nur einmal am Anfang
Will ich
Will ich
Will ich
Will ich
Will ich
Will ich nur einmal am Ende
Mit Python ging es dann recht einfach, elegant und ausreichend performant (3 jeweils über 100 MB große Dateien ließen sich in ungefähr 12 Sekunden kombinieren):
- Die zu kombinierenden Dateien speichere ich in einem Array, hinzu kommt die Angabe des Ausgabepfads. Diese Information könnte man gegebenenfalls auch aus dem Dateisystem holen.
- Wir öffnen die Ausgabedatei zum Schreiben
- und nutzen dann ein enumerate, um den Zähler zu bekommen, bei welcher Datei wir gerade sind
- Bearbeiten wir die erste Datei, so brauchen wir alles bis auf die letzte Zeile
- Bearbeiten wir die letzte Datei, so brauchen wir nicht die ersten beiden Zeilen
- Bei den Dateien 2 bis n-1 brauchen wir weder die ersten zwei noch die letzte Zeile
files = ['f:/willich.txt', 'f:/willich.txt', 'f:/willich.txt']
output = 'F:/kombiniert.txt'
filecount = len(files)
print(f'Processing {filecount} files')
with open(output, 'w') as outputfile: # Ausgabe öffnen
for counter, file in enumerate(files):
print(counter, file)
with open(file, 'r') as fin:
data = fin.read().splitlines(True)
if counter == 0: # Erste Datei: alles bis auf die letzte Zeile
outputfile.writelines(data[:-1])
elif counter == filecount - 1: # letzte Datei, alles bis auf die ersten zwei Zeilen
outputfile.writelines(data[2:])
else: # die Dateien zwischen erster und letzter Datei, nicht die beiden ersten und die letzte Zeile
outputfile.writelines(data[2:-1]) |
files = ['f:/willich.txt', 'f:/willich.txt', 'f:/willich.txt']
output = 'F:/kombiniert.txt'
filecount = len(files)
print(f'Processing {filecount} files')
with open(output, 'w') as outputfile: # Ausgabe öffnen
for counter, file in enumerate(files):
print(counter, file)
with open(file, 'r') as fin:
data = fin.read().splitlines(True)
if counter == 0: # Erste Datei: alles bis auf die letzte Zeile
outputfile.writelines(data[:-1])
elif counter == filecount - 1: # letzte Datei, alles bis auf die ersten zwei Zeilen
outputfile.writelines(data[2:])
else: # die Dateien zwischen erster und letzter Datei, nicht die beiden ersten und die letzte Zeile
outputfile.writelines(data[2:-1])
2022-03-19, 20:02
Neben der Nutzung der scrlttr2 Klasse gibt es in aktuelleren KOMA-Script Versionen auch die Möglichkeit, das scrletter-Paket zu nutzen. Hier ein Beispiel:
\documentclass[12pt,ngerman]{scrartcl}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{booktabs}
\usepackage{babel}
\usepackage{graphicx}
\usepackage{csquotes}
\usepackage{paralist}
\usepackage{xcolor}
\usepackage{palatino}
\usepackage{blindtext}
\usepackage{scrletter}
\setkomavar{fromname}{Max Mustermann}
\setkomavar{fromemail}{Max@Mustermann.de}
\setkomavar{fromaddress}{Musterweg 221, 12345 Musterstadt}
\setkomavar{firstfoot}{\usekomavar{fromemail}}
\begin{document}
\begin{letter}{Maria Mustermann \\ Mustergasse 1 \\ 12346 Musterstadt}
\opening{Hallo Maria,}
\blindtext[2]
\closing{Mit freundlichen Grüßen}
\end{letter}
\end{document} |
\documentclass[12pt,ngerman]{scrartcl}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{booktabs}
\usepackage{babel}
\usepackage{graphicx}
\usepackage{csquotes}
\usepackage{paralist}
\usepackage{xcolor}
\usepackage{palatino}
\usepackage{blindtext}
\usepackage{scrletter}
\setkomavar{fromname}{Max Mustermann}
\setkomavar{fromemail}{Max@Mustermann.de}
\setkomavar{fromaddress}{Musterweg 221, 12345 Musterstadt}
\setkomavar{firstfoot}{\usekomavar{fromemail}}
\begin{document}
\begin{letter}{Maria Mustermann \\ Mustergasse 1 \\ 12346 Musterstadt}
\opening{Hallo Maria,}
\blindtext[2]
\closing{Mit freundlichen Grüßen}
\end{letter}
\end{document}

2022-03-06, 15:24
Mit dem folgenden Befehl kann man in Windows Netzlaufwerke (z.B. Freigaben auf einem Synology NAS) mounten
net use s: \\Diskstation4\Bilder /user:uwe passwort
Mittels net use * /delete lassen sich alle verbundenen Freigaben beenden.
2022-03-05, 22:24
Mit dem folgenden Schnipsel kann man den Pfad der Python.exe bestimmen, die das aktuelle Programm ausführt
import sys
print(sys.executable) |
import sys
print(sys.executable)
2022-02-26, 13:10
Hier ein Beispiel für das XCharter Paket, das einen passenden Mathe-Font für die Charter bereitstellt.
%!TEX TS-program = LuaLaTeX
\documentclass[12pt,ngerman]{scrartcl}
\usepackage{fontspec}
\usepackage{babel}
\usepackage{unicode-math}
\setmathfont{XCharter-Math.otf} % Call by file name or
\setmathfont{XCharter Math} % Call by font name
\setmainfont{XCharter}
\setsansfont{Cabin}[Scale=MatchLowercase] % sf
\setmonofont{Inconsolatazi4}[Scale=MatchLowercase] % tt
\usepackage{blindtext}
\begin{document}
\blindtext
\begin{equation}
\int_{x=1}^{\infty} -\frac{p}{2} \pm \sqrt{ \left(\frac{p}{2} \right)^2 -q }
\end{equation}
\blindtext
\end{document} |
%!TEX TS-program = LuaLaTeX
\documentclass[12pt,ngerman]{scrartcl}
\usepackage{fontspec}
\usepackage{babel}
\usepackage{unicode-math}
\setmathfont{XCharter-Math.otf} % Call by file name or
\setmathfont{XCharter Math} % Call by font name
\setmainfont{XCharter}
\setsansfont{Cabin}[Scale=MatchLowercase] % sf
\setmonofont{Inconsolatazi4}[Scale=MatchLowercase] % tt
\usepackage{blindtext}
\begin{document}
\blindtext
\begin{equation}
\int_{x=1}^{\infty} -\frac{p}{2} \pm \sqrt{ \left(\frac{p}{2} \right)^2 -q }
\end{equation}
\blindtext
\end{document}

2021-12-23, 20:35
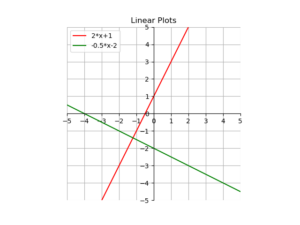
Hier ein kurzes Beispiel, wie man mit matplotlib Funktionen plotten kann.
import matplotlib.pyplot as plt
import numpy as np
ax = plt.gca()
plt.gca().set_aspect('equal')
ax.set_xticks(range(-6,6,1))
ax.set_yticks(range(-6,6,1))
ax.set_xlim([-5, 5])
ax.set_ylim([-5, 5])
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_position('zero')
ax.spines['left'].set_position('zero')
ax.spines['right'].set_color('none')
x = np.linspace(-5,5,100)
y = 2*x+1
y2 = -0.5*x-2
plt.plot(x, y, 'r', label='2*x+1')
plt.plot(x, y2, 'g', label='-0.5*x-2')
plt.title('Linear Plots')
plt.legend(loc='upper left')
plt.grid()
plt.show() |
import matplotlib.pyplot as plt
import numpy as np
ax = plt.gca()
plt.gca().set_aspect('equal')
ax.set_xticks(range(-6,6,1))
ax.set_yticks(range(-6,6,1))
ax.set_xlim([-5, 5])
ax.set_ylim([-5, 5])
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_position('zero')
ax.spines['left'].set_position('zero')
ax.spines['right'].set_color('none')
x = np.linspace(-5,5,100)
y = 2*x+1
y2 = -0.5*x-2
plt.plot(x, y, 'r', label='2*x+1')
plt.plot(x, y2, 'g', label='-0.5*x-2')
plt.title('Linear Plots')
plt.legend(loc='upper left')
plt.grid()
plt.show()
2021-12-23, 20:14
Angenommen, wir haben eine Excel-Datei Daten.xlsx mit Werten, die in ein entsprechendes XML-Dokument überführt werden müssen.
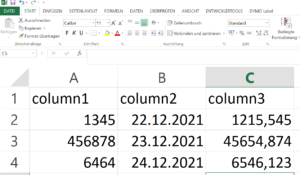
Mit Python und der Jinja2 Template-Engine ist das flink gemacht. Zuerst definieren wir das Template template.xml:
<?xml version='1.0' encoding='UTF-8'?>
<table name="Tablename">
{% for _,row in data.iterrows() %}
<ROW>
<COLUMN1>{{row['column1']}}</COLUMN1>
<COLUMN2>{{row['column2']}}</COLUMN2>
<COLUMN3>{{row['column3']}}</COLUMN3>
</ROW>
{% endfor %}
</table> |
<?xml version='1.0' encoding='UTF-8'?>
<table name="Tablename">
{% for _,row in data.iterrows() %}
<ROW>
<COLUMN1>{{row['column1']}}</COLUMN1>
<COLUMN2>{{row['column2']}}</COLUMN2>
<COLUMN3>{{row['column3']}}</COLUMN3>
</ROW>
{% endfor %}
</table>
Dann definieren wir den Python-Code:
import pandas as pd # data wrangling
import jinja2 # template engine
import os # for file-related stuff
# create jinja env that can load template from filesystem
jinja_env = jinja2.Environment(loader = jinja2.FileSystemLoader(os.path.abspath('.')))
df = pd.read_excel('Daten.xlsx')
template = jinja_env.get_template('template.xml')
with open('FertigesXML.xml','w') as output:
output.write(template.render(data=df)) |
import pandas as pd # data wrangling
import jinja2 # template engine
import os # for file-related stuff
# create jinja env that can load template from filesystem
jinja_env = jinja2.Environment(loader = jinja2.FileSystemLoader(os.path.abspath('.')))
df = pd.read_excel('Daten.xlsx')
template = jinja_env.get_template('template.xml')
with open('FertigesXML.xml','w') as output:
output.write(template.render(data=df))
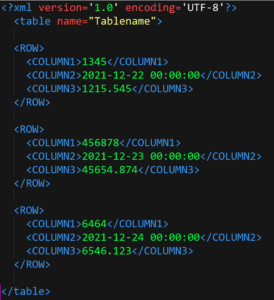
Lassen wir den Python-Code laufen, so erhalten wir das folgende XML:
2021-09-25, 10:51
A while ago (https://www.uweziegenhagen.de/?p=2373) I had an article on how to read the ECB fx rates file with Python. Some time has passed, there are other options in Python 3.
Option 1: Make the Python 2 code run with Python 3
import xml.etree.ElementTree as ET
import urllib.request
root = ET.parse(urllib.request.urlopen('http://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml')).getroot()
for child in root[2][0]:
curr = child.get('currency')
rate = child.get('rate')
print(curr, rate) |
import xml.etree.ElementTree as ET
import urllib.request
root = ET.parse(urllib.request.urlopen('http://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml')).getroot()
for child in root[2][0]:
curr = child.get('currency')
rate = child.get('rate')
print(curr, rate)
Option 2: Use pandas >=1.3
Starting with version 1.3 pandas offers the read_xml command, so upgrade using
pip3 install --upgrade pandas or conda update pandas.
from urllib.request import urlopen
import pandas as pd
df = pd.read_xml(urlopen('http://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml'),xpath='//*[@currency]')
print(df) |
from urllib.request import urlopen
import pandas as pd
df = pd.read_xml(urlopen('http://www.ecb.europa.eu/stats/eurofxref/eurofxref-daily.xml'),xpath='//*[@currency]')
print(df)